TL;DR
- Most teams start AI feature planning at the wrong layer. The first question is not which model to use. It is whether AI is the right tool for the problem at all.
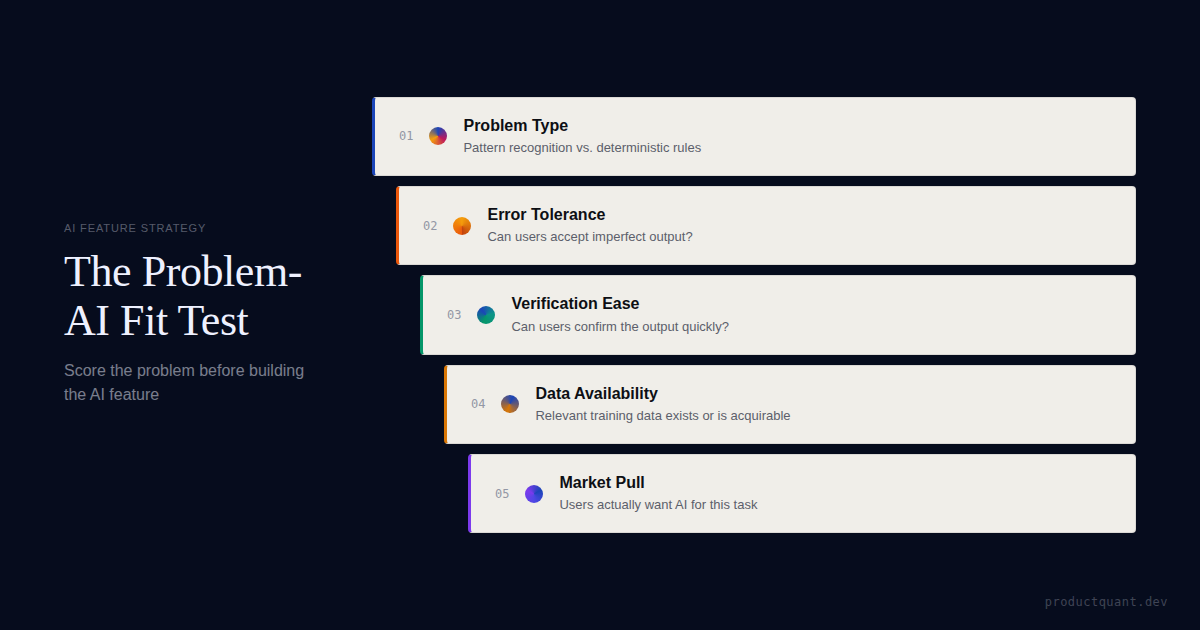
- A strong AI feature needs 5 conditions: tolerable errors, verifiable output, real workflow value, usable data, and a feedback loop that compounds quality over time.
- A no-go decision is often a better product decision than a rushed AI launch. The right outcome of an AI feature review is not always "ship" — sometimes it is "solve this with rules, UX, or process design instead."
- The 10-question scorecard below takes 20 minutes and covers problem type, error tolerance, verification ease, bottleneck severity, data availability, usage frequency, value per output, user willingness, feedback loop quality, and competitive pressure.
Every product team has been in this meeting.
An executive reads a report about a competitor shipping an AI feature. A customer asks for AI during a QBR. A board member mentions AI on the earnings call. The message is always the same: "We need an AI feature."
The team responds the way teams always do. They debate model vendors. They build prototypes. They prototype a chat interface. They argue about whether to wrap, fine-tune, or build. They plan the launch messaging.
And somewhere between the demo and the launch, they discover the uncomfortable truth: nobody asked whether this problem actually needed AI.
The evidence that this mistake is widespread is not subtle. CompTIA's 2025 survey of over 1,100 U.S. businesses found that 79% of companies have already backtracked on AI initiatives after they failed to meet business objectives — with 52% citing underperforming AI as the primary failure point (CompTIA, 2025). Half of those companies struggle to scale AI for complex tasks. Nearly half report that the technology costs outweigh the anticipated ROI.
A separate analysis of AI SaaS product failures found that 80% to 98% of AI and ML projects fail, with only 13% of companies reporting that they see enterprise value from their investments (Smith, 2025). The most common failure mode is not bad models or poor engineering. It is building AI for problems that should have been solved with rules, better UX, or process design.
This is not theoretical. GitHub Copilot is one of the most successful AI features in history because it passes every dimension of the framework below — it is pure pattern recognition, developers verify every suggestion, the feedback loop is a single keystroke, and competitive pressure is intense. BlueOptima's research confirms a 5.4% productivity uplift among Copilot users, scaling to 20% for the most engaged (BlueOptima, 2026). AI email auto-reply, by contrast, scores much lower on the framework — not because the technology is weak, but because error tolerance is near-zero and users are nervous about autonomous sending. The difference between these two is not model capability. It is problem fit.
The test below takes 20 minutes and prevents the most expensive mistake a product team can make: shipping a technically impressive feature that nobody trusts, adopts, or values.
What Counts as Real AI Fit?

AI — pattern recognition, generation, or prediction — is not a universal solvent. It is a specific tool with specific strengths and specific failure modes.
AI is the right tool when the problem involves:
- Pattern recognition at scale. Finding structure in data that humans can sense but cannot process fast enough. Spam detection, lead scoring, content moderation.
- Generation. Producing novel content — text, code, images, summaries — where there is no single correct answer but quality can be judged. Email drafts, code completions, meeting summaries.
- Prediction. Estimating future outcomes from historical patterns. Churn risk, demand forecasting, inventory optimization.
AI is the wrong tool when the problem is actually:
- Data retrieval. "Show me last quarter's invoices." That is a database query, not an AI problem.
- Deterministic rules. "Flag expenses over $10,000." That is an if-then statement.
- Basic calculation. "What is our burn rate?" That is arithmetic.
- Workflow friction caused by UX. "Users cannot find the export button." That is a design problem, not an AI problem.
The teams that waste the most on AI are not the ones picking the wrong model. They are the ones applying AI to problems that would be solved more reliably, more cheaply, and faster with rules, better design, or process change.
| Signal | AI is likely right | AI is likely wrong |
|---|---|---|
| Problem type | Pattern recognition, generation, or prediction at scale | Retrieval, rules, calculation, or UX friction |
| Error tolerance | Users can catch and correct mistakes | A single error has serious consequences |
| Verification | Users can verify output at a glance | Only domain experts can verify, and even then |
| Bottleneck | Current process is slow, expensive, or inconsistent | Current process works fine |
| Data | Thousands of examples exist or can be generated | Must create data from scratch |
"The difference between a successful AI feature and an expensive demo is not model quality. It is whether the problem deserved AI in the first place."
— Jake McMahon, ProductQuant
Can the User Trust the Result Enough to Use It?
Even when AI is the right tool for the problem, adoption fails if users cannot trust the output. Trust has 2 components: error tolerance and verification ease.
Error tolerance
Every AI makes mistakes. LLMs hallucinate. Classifiers misclassify. Predictive models have false positives and false negatives. The question is not whether the system can be perfect — it cannot. The question is what happens when it is wrong.
Code completion tolerates errors because the developer reviews every suggestion before accepting it. Wrong code is simply not accepted. Autonomous email auto-reply does not tolerate errors because sending the wrong message to a client can destroy a relationship. The same technology, different error consequences, entirely different strategic outcomes.
Ruben Dominguez puts the asymmetry precisely: one bad output has more impact than 10 good results (Dominguez, 2025). A single confident hallucination or critical failure feels catastrophic to users. Once burned, they rarely return.
Verification ease
If users cannot tell whether the AI output is correct, they either trust it blindly — dangerous — or do not trust it at all — useless. Verification ease is the gap between these 2 failure modes.
Generated text is easy to verify: does it read well, does it say the right thing, would you send it? Churn prediction is harder to verify: you only know it worked if the customer stays or leaves weeks later. Hidden wrong answers are worse than visible rough answers. Users can work with a system that is visibly imperfect. They cannot work with a system that is confidently wrong.
A Wharton study from early 2026 found that people follow AI recommendations 79.8% of the time even when the AI is wrong (Wharton, 2026). The counterintuitive finding: as AI becomes more reliable, it becomes harder and more expensive to motivate humans to oversee it effectively. Better AI does not automatically produce better outcomes if users cannot verify what it produces.
Users will adopt an AI feature that is visibly imperfect but verifiable. They will abandon an AI feature that is occasionally wrong but impossible to check.
Is the Value Big Enough to Justify the Complexity?

AI features carry overhead that simpler features do not. They need data pipelines, model monitoring, output validation, and feedback loops. If the value per interaction is trivial, the complexity outweighs the benefit. An analysis of failed AI SaaS products found that fine-tuning a custom generative model costs $5M to $20M, plus ongoing infrastructure and token fees (Smith, 2025). Even when the technology works, the value must justify that investment.
3 dimensions determine whether the value is real:
- Bottleneck severity. Is the current process a genuine pain point, or just "nice to improve"? AI should replace or augment something that is painfully slow, expensive, or inconsistent. CompTIA found that 47% of AI failures trace back to integration problems with existing workflows (CompTIA, 2025). If the current process works fine, AI adds cost without proportional value.
- Usage frequency. Features used daily have more opportunities to build trust, generate data, and justify their cost than features used monthly. A feature that saves 30 minutes but is used once a quarter generates less value than one that saves 2 minutes but is used 20 times a day.
- Value per correct output. Each correct output should save meaningful time, prevent a real error, or enable something that was not possible before. Novelty is not value. Users do not adopt features because they are AI-powered. They adopt them because they make a specific task easier, faster, or better.
Do You Have the Raw Material to Improve the Feature?
AI needs data. The type and volume depend on the approach — zero-shot LLM features need no training data, RAG needs 50 to 500 documents, fine-tuning needs 500 to 10,000 input-output pairs — but all of them need something.
Two questions determine whether you have the raw material:
Data availability. Do you have enough relevant examples, documents, or historical records to support the AI approach? If the answer is "we would need to create data from scratch," the feature is not ready. It is a data problem dressed as an AI problem.
Feedback loop quality. Can you measure whether the AI output was useful? A good feedback loop means every interaction generates labeled data that makes the system better. Code completion has a perfect feedback loop — tab means accept, keep typing means reject. Meeting summarization has a weaker loop — users can edit the summary, but most will not. AI features that improve over time are dramatically more valuable than static ones. If you cannot measure improvement, you are shipping a snapshot, not a system.
Data readiness comes after fit, before build
Once a feature passes the fit test, the next question is whether the data foundation can support it for the median customer, not just the cleanest account.
Will the Market Actually Pull This Into Use?
A feature can score well on problem type, trust, value, and data — and still fail because users do not want it.
User willingness is partly about trust and partly about identity. Some tasks feel deeply personal — creative expression, relationship management — and users resist AI involvement regardless of output quality. Other tasks are universally disliked — data entry, expense categorization — and users actively want AI to take them over.
The signal to watch for: are users already using external AI tools for this task? If yes, the willingness is proven. If no, but users are asking for it, the willingness is developing. If users are neither using tools nor asking for help, the demand may be executive anxiety rather than market pull.
Competitive pressure matters, but not the way most teams think. If competitors are shipping similar features and gaining adoption, waiting is risky. But competitor presence does not validate a feature with poor fit. It validates that someone else made the same mistake. The right question is whether the competitor is solving the right problem well, not whether they shipped first.
The 10-Question Scorecard
Score each question 1 to 5. Be honest. Optimistic scoring leads to failed features. When in doubt, score lower.
| Question | 1 point | 3 points | 5 points |
|---|---|---|---|
| 1. Is the problem about pattern recognition, generation, or prediction? | No — it is retrieval, rules, or calculation | Pattern matters but is not the only component | The core value comes from pattern or generation |
| 2. How tolerant is the use case of errors? | Zero tolerance — a single error is catastrophic | Errors are annoying but users can catch and correct them | Errors are expected and users naturally filter them |
| 3. Can users easily verify the AI output? | Impossible — only experts can verify, and even they struggle | Users can verify with some effort | Correctness is immediately obvious |
| 4. Is the current process a genuine bottleneck? | No bottleneck — the current process is adequate | Regularly causes delays or frustration | The current process is the number 1 pain point |
| 5. How much data is available? | No relevant data — must create from scratch | Hundreds to thousands of examples | Massive, well-organized dataset with clear labels |
| 6. How frequently will users use this? | Rarely — once a quarter or less | Weekly | Multiple times per day, integrated into core workflow |
| 7. How valuable is each correct output? | Trivial — saves seconds, marginal convenience | Saves 15 to 30 minutes or meaningful quality improvement | Saves hours, prevents major errors, or enables new capabilities |
| 8. Are users willing to use AI for this task? | Strong resistance — users explicitly reject AI for this | Neutral — open but not requesting | Enthusiastic — already using external AI tools for this |
| 9. Can you build a feedback loop? | No way to measure whether the output was useful | Can track accept or reject signals | Every interaction generates labeled training data |
| 10. Is there competitive pressure? | No pressure — no competitors, no customer demand | Competitors are beta testing, market is paying attention | Competitors are gaining share and deals are being lost |
Score interpretation
| Score | Fit level | Recommended move |
|---|---|---|
| 40 to 50 | Excellent fit | Proceed to data readiness assessment with confidence. This is the kind of problem AI was built to solve. |
| 30 to 39 | Good fit | Viable with concerns. Identify the lowest-scoring questions and determine if the gaps can be addressed. Proceed with a mitigation plan. |
| 20 to 29 | Marginal fit | Proceed with caution. A simpler, non-AI solution may achieve 80% of the benefit at 20% of the cost. Compare both approaches before committing. |
| 10 to 19 | Poor fit | AI is likely the wrong approach. Reassess the problem. Consider rule-based systems, better UX design, process improvements, or additional staffing. |
Regardless of the total score, any of these 4 conditions should stop the feature: near-zero error tolerance with no human-in-the-loop, output that users cannot verify, no relevant data with no path to acquire it, or users who explicitly reject AI for this task.
What to Do After the Score
The scorecard produces a number. The right move requires judgment. Here is the decision tree:
| Result | What it means | Next step |
|---|---|---|
| 40 to 50, no red flags | Strong AI opportunity | Move to data readiness assessment, then build, buy, or wrap decision |
| 30 to 39, with identifiable gaps | Viable but not clean | Write a mitigation plan for each weak question. If the gaps are fixable, proceed. If not, downgrade to marginal. |
| 20 to 29 | AI may be overkill | Design a non-AI alternative. If the non-AI version gets close, build that first. If AI is clearly superior, proceed with narrow scope. |
| 10 to 19 or any red flag | Wrong tool for this problem | Do not build. Solve it with rules, UX, or process design. Revisit if the conditions change. |
The right sequence for AI features is: fit test, data readiness, build or buy decision, UX design, launch instrumentation. Teams that skip the first layer and start at model choice ship features that are technically excellent and strategically misaligned.
If the feature passes the fit test, the next problem is launching it with the right measurement, taxonomy, and Day-30 verdict
AI Feature Launch covers value-moment definition, event taxonomy, repeat-use measurement, and the Day-30 readout framework — the infrastructure that makes an AI feature earn its keep.
Frequently Asked Questions
Can a low-scoring AI idea still be worth piloting?
Sometimes, if the pilot is cheap and the learning is valuable. But a low score means the team should treat it as an experiment, not a roadmap commitment, and set a clear kill-criteria before spending engineering time. CompTIA found that 64% of companies used AI to justify unpopular business decisions, which suggests many pilots become sunk-cost commitments rather than genuine experiments. The difference is whether the team defines success as learning or as shipping.
What if competitors already shipped something similar?
Competitor presence raises the urgency score on the scorecard — that is question 10 — but it does not change the fit score on questions 1 through 9. A feature with poor fit will fail even if everyone ships it, because users will not adopt something that does not solve their actual problem well. The right question is whether the competitor is solving the right problem effectively, not whether they shipped first. Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025, but adoption quality matters more than adoption speed.
How much data is enough for an AI feature?
Enough depends entirely on the approach you plan to use. Zero-shot LLM features need no training data — they use the model's general knowledge. RAG workflows need 50 to 500 well-indexed documents to retrieve from. Fine-tuned models need 500 to 10,000 high-quality input-output pairs. The audit should check volume against the specific approach, not against a generic threshold. If you do not have enough data for any approach, that is a data readiness problem, not an AI strategy problem.
Should we score the feature before or after vendor evaluation?
Before, always. The fit test determines whether AI belongs in the product at all. Vendor choice — build, buy, or wrap — is a downstream decision that only matters if the answer to question 1 is yes. Teams that evaluate vendors before confirming fit often buy tools for problems that do not need AI, which is one reason why CompTIA found that 48% of companies report technology costs exceeding their anticipated AI ROI.
What if users say they want AI but do not use it later?
That is a willingness signal, not necessarily a fit failure. Users often express interest in AI features they never adopt because the problem did not warrant AI, the output was not verifiable, or the feature did not integrate into their actual workflow. The fit test catches this before launch by scoring user willingness alongside verification ease and bottleneck severity. If willingness scores high but adoption stays low, the gap is usually in workflow integration, not in the AI capability itself.

Jake McMahon
Jake founded ProductQuant to help B2B SaaS teams make product decisions with evidence, not intuition. He has guided 40+ teams through AI feature strategy, growth system design, and competitive positioning. Book an AI Feature Launch diagnostic →
Sources
- CompTIA — AI's Impact on Productivity and the Workforce (September 2025, N=1,100+ U.S. businesses) — 79% backtrack rate, 52% underperforming AI, 47% integration problems
- Smith, D. — 5 Reasons AI SaaS Product Fail (August 2025) — 80-98% AI/ML failure rate, $5M-$20M fine-tuning cost, 5 failure modes
- Wharton — When Better AI Makes Oversight Harder (March 2026) — Human-AI contracting paradox, rising oversight costs
- Dominguez, R. — AI Hype vs Reality: Trust Gap (December 2025) — 1:10 failure asymmetry, trust-based abandonment
- BlueOptima — The Impact of GitHub Copilot on Developer Performance (February 2026) — 5.4% productivity uplift
- Gartner — 40% of Enterprise Apps Will Feature AI Agents by 2026 (August 2025)
- AppVerticals — SaaS Statistics 2026 (April 2026) — 95% AI SaaS adoption, 64% new products have AI features
- ProductQuant AI Feature Strategy Framework — 10-question Problem-AI Fit Analyzer, 20 scored examples, 6-layer opportunity assessment
If the feature passes the fit test, the next problem is launching it right
AI Feature Launch gives you the value-moment definition, event taxonomy, and Day-30 readout framework — the infrastructure that makes an AI feature earn its keep.